node.js爬虫入门(二)爬取动态页面(puppeteer)
3389 72 1 技术 2020-04-15
之前第一篇爬虫教程node.js爬虫入门(一)爬取静态页面讲解了静态网页的爬取,十分简单,但是遇到一些动态网页(ajax)的话,直接用之前的方法发送请求就无法获得我们想要的数据。这时就需要通过爬取动态网页的方法,selenium和puppeteer都不错。
这里推荐使用puppeteer,不为别的,只因为他是谷歌亲生的,一直在维护更新。下面是翻译的官方文档 )介绍
Puppeteer 是一个提供一系列高级接口通过 DevTools(开发者工具)协议去控制 Chrome 或者 Chromium(谷歌开源)的 Node 库。它默认运行无头模式(没有浏览器的UI界面),通过配置也可以运行正常模式。
它能用来:
- 网页截图和导出PDF
- 爬取SPA和SSR网站
- 自动化表单提交、界面测试、键盘输入等
- 创建一个最新的自动化测试环境,直接使用最新的chrome版本和JS特性进行测试
- 捕获网站的时间线轨迹用以帮助诊断性能问题
- 测试谷歌浏览器的扩展程序
首先我们还要先安装再使用,默认安装的时候会附带下载一个最新的Chromium,300M左右大小。
npm install puppeteer
如果你本机已经有较新版本的chrome,那么可以仅安装核心版本,但是启动puppeteer的时候要配置本地chrome的路径。
npm install puppeteer-core // 核心版本
假设我们现在要爬取拉勾网前端招聘信息,这个是动态页面,使用这个例子下面来尝试爬取。
因为chrome操作全是异步操作,为了避免回调地狱,推荐使用es7的async await,这种语法可读性高,官方文档也是如此。
- 首先使用puppeteer启动浏览器并打开该动态页面
需要注意这里如果是使用本地浏览器的话则需要在启动浏览器配置中传入本地chrome路径
const browser = await puppeteer.launch({
executablePath: 'C:/Users/Administrator/AppData/Local/Google/Chrome/Application/chrome.exe'
})
- 在chrome环境中执行函数,以获取所需的数据,然后返回给node的执行环境
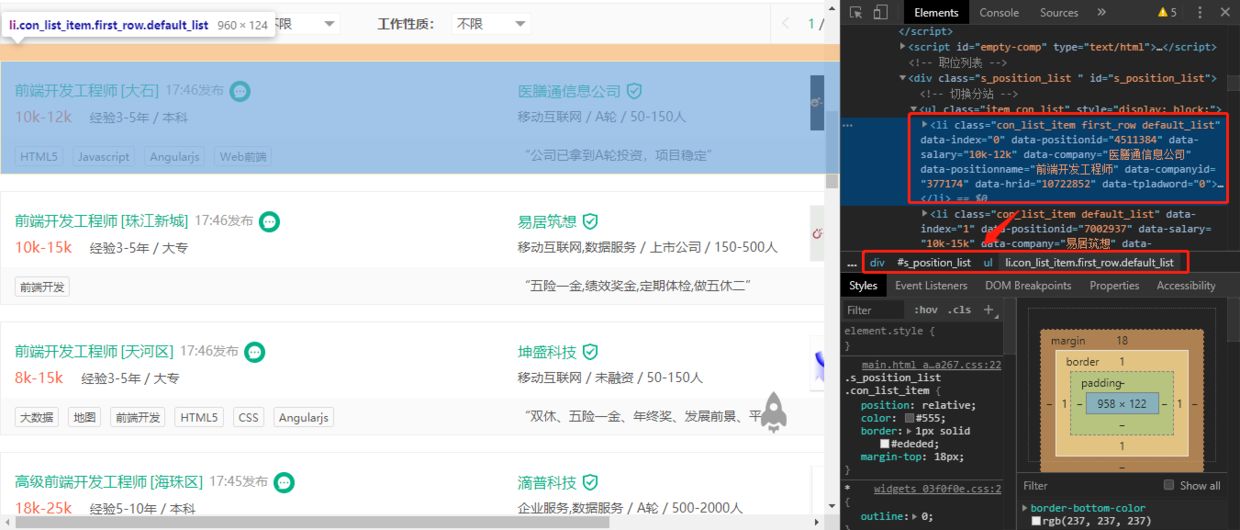
上图可以看到我们所需数据的dom位置,chrome环境执行的函数中我们要获取并组织所需的数据。
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
这里有个调试小技巧,获取数据的函数我们可以直接在chrome的控制台中写,以便于调试
最后附上完整的代码
const puppeteer = require('puppeteer');
(async () => {
// 启动浏览器
const browser = await puppeteer.launch({
headless: false, // 默认是无头模式,这里为了示范所以使用正常模式
})
// 控制浏览器打开新标签页面
const page = await browser.newPage()
// 在新标签中打开要爬取的网页
await page.goto('https://www.lagou.com/jobs/list_web%E5%89%8D%E7%AB%AF?px=new&city=%E5%B9%BF%E5%B7%9E')
// 使用evaluate方法在浏览器中执行传入函数(完全的浏览器环境,所以函数内可以直接使用window、document等所有对象和方法)
let data = await page.evaluate(() => {
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
})
console.log(data)
})()
运行结果
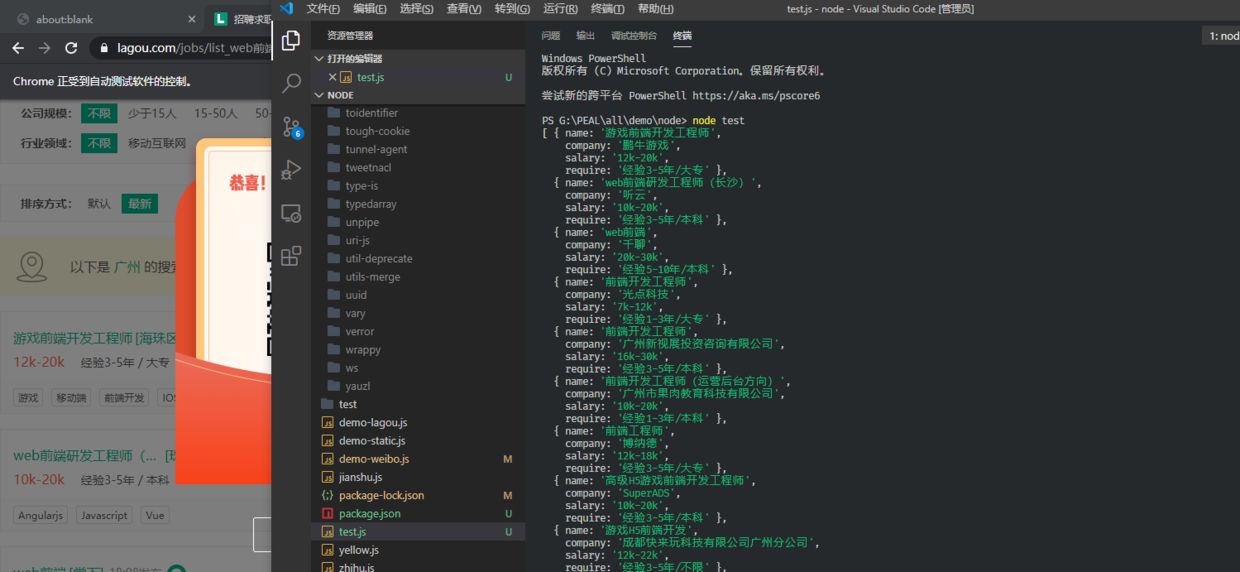
到这里动态网页的爬取也完成了,但是puppeteer功能远不止于此,它还有很多强大API可以使用。可以移步官方文档 )。
第三期会讲讲怎么定时执行爬虫并进行数据库存储。
「 感觉不错就给个赞吧 ~ 」

km
2024-03-02 15:40